
机器学习简介
机器学习是从数据中自动分析获得模型, 并利用模型对位置数据进行预测.
机器学习的工作流程
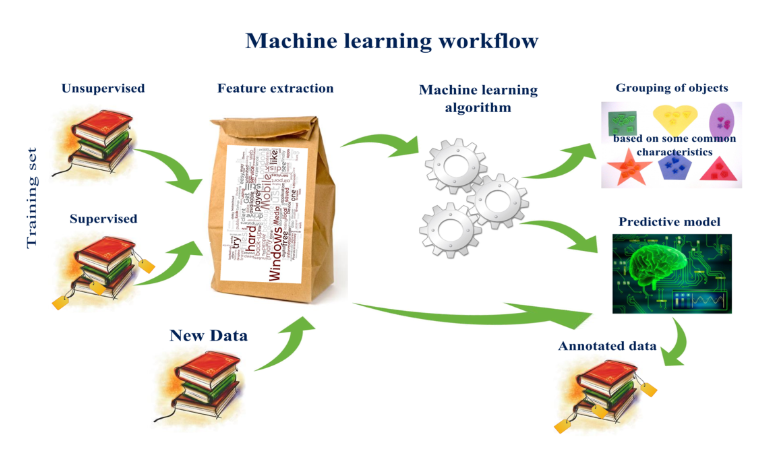
获取数据
在数据集中一般:
- 一行数据我们称为一个
样本 - 一列数据我们成为一个
特征
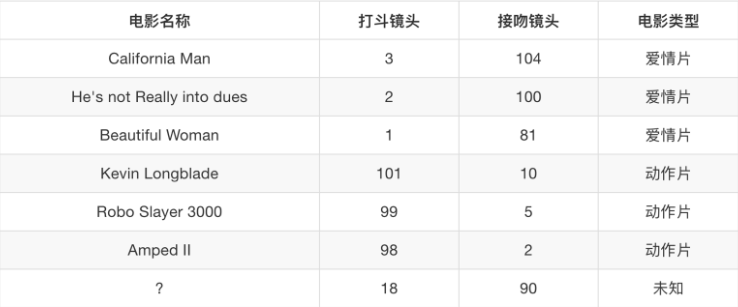
有些数据有目标值(标签值),有些数据没有目标值(如上表中,电影类型就是这个数据集的目标值)
数据类型构成:
- 数据类型一:特征值+目标值(目标值是连续的和离散的)
- 数据类型二:只有特征值,没有目标值
数据的基本处理
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
特征工程
将数据转换成数学公式能够表达的过程, 复杂的说就是利用数据领域的知识,创建能让机器学习算法性能最大化的过程.
机器学习领域的大神Andrew Ng(吴恩达)老师说“Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering. ”
特征的分类
- 原始特征和高级特征
- 原始特征: 不需要或者极少的人工干预和处理. 比如文本特征的词向量特征,图片中的像素点
- 高级特征: 结合业务逻辑或者模型,规则之类的复杂处理得到的特征,比如明星综合实力,学生综合素质.
- 非实时特征和实时特征
- 非实时特征: 指的是变化频率比较少的特征,比如,商品单价
- 实时特征: 频繁更新的特征,比如步速,比如股票走势
- 离散值特征和连续值特征

特征预处理
特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程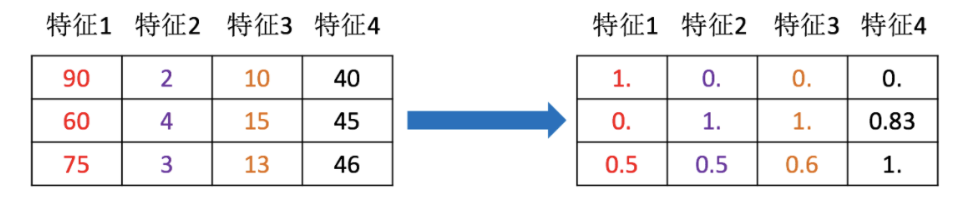
特征降维
特征降维:指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程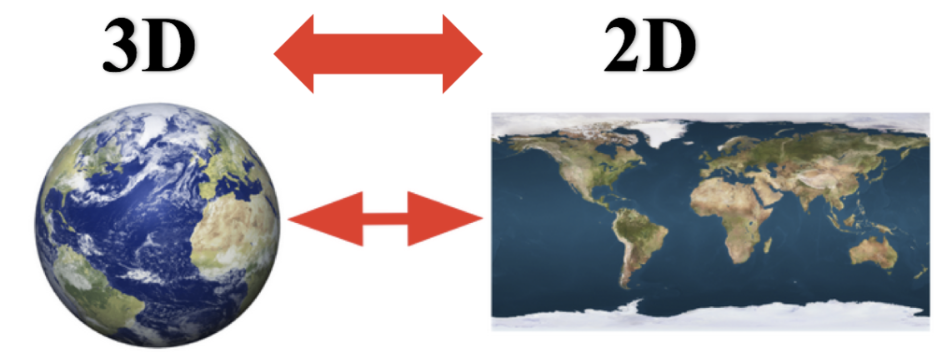
机器学习(模型训练)
使用训练集进行训练
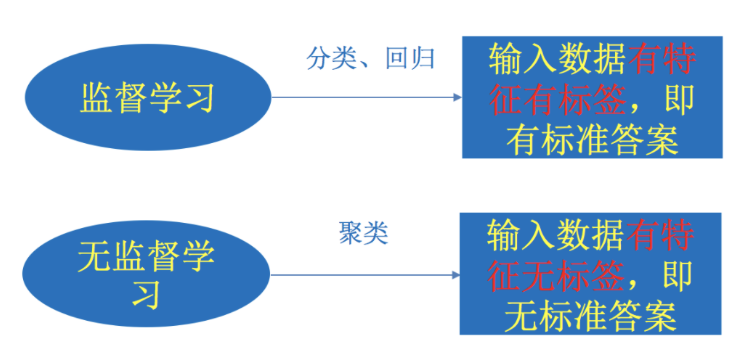
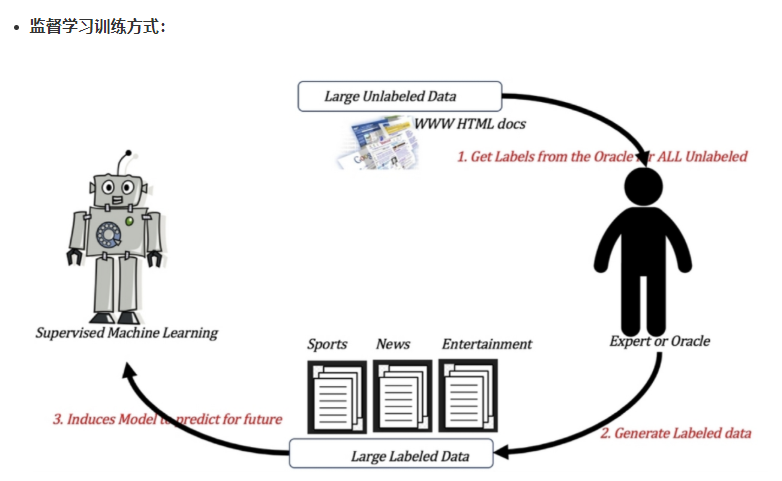
监督学习
输入数据是由输入特征值和目标值所组成。
- 函数的输出可以是一个连续的值(称为回归),
- 或是输出是有限个离散值(称作分类)。
回归问题
例如:预测房价,根据样本集拟合出一条连续曲线。
分类学习
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性”或者“恶性”,是离散的。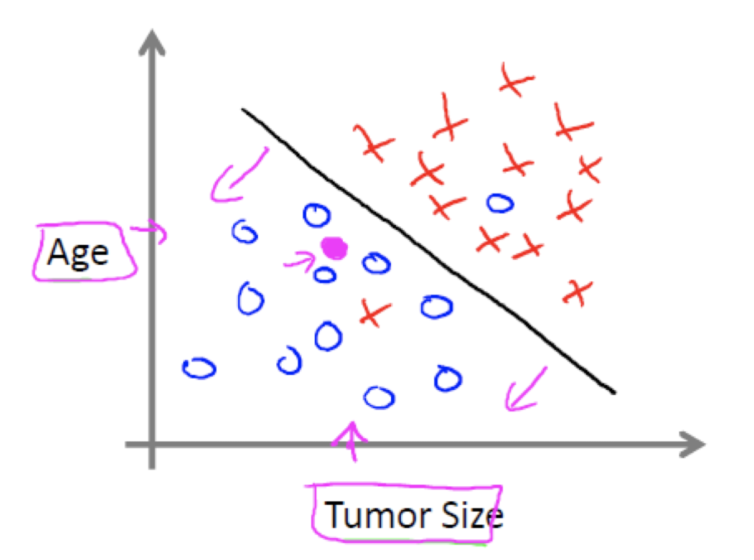
无监督学习
输入数据是由输入特征值组成。
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。
有无监督学习的对比
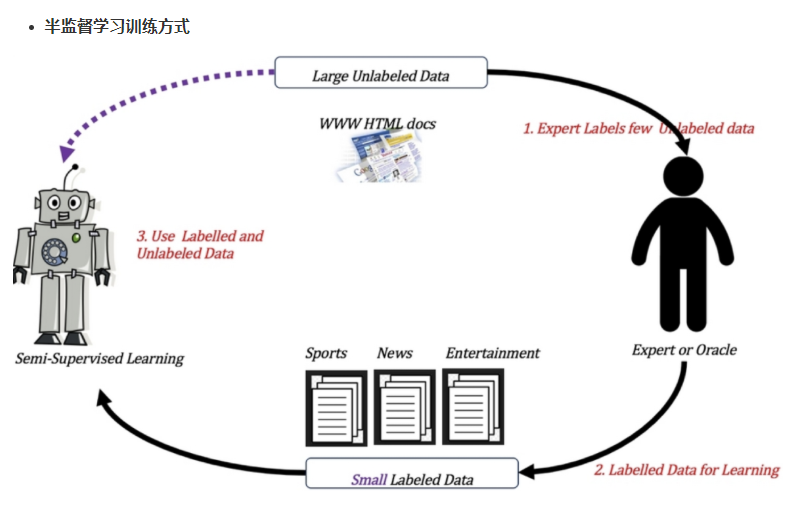
半监督学习
强化学习
强化学习:实质是,make decisions 问题,即自动进行决策,并且可以做连续决策。
小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
小孩就是 agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
主要包含四个元素:agent,环境状态,行动,奖励.

监督学习和强化学习的对比
| ` | 监督学习 | 强化学习 |
|---|---|---|
| 反馈映射 | 输入到输出的一个映射,监督式学习输出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出。 | 输入到输出的一个映射,强化学习输出的是给机器的反馈 reward function,即用来判断这个行为是好是坏。 |
| 反馈时间 | 做了比较坏的选择会立刻反馈给算法。 | 结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏。 |
| 输入特征 | 输入是独立同分布的。 | 面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入。 |
| 行为模式 | 不考虑行为间的平衡,只是开发(exploitation) | 一个 agent 可以在探索和开发(exploration and exploitation)之间做权衡,并且选择一个最大的回报。 |
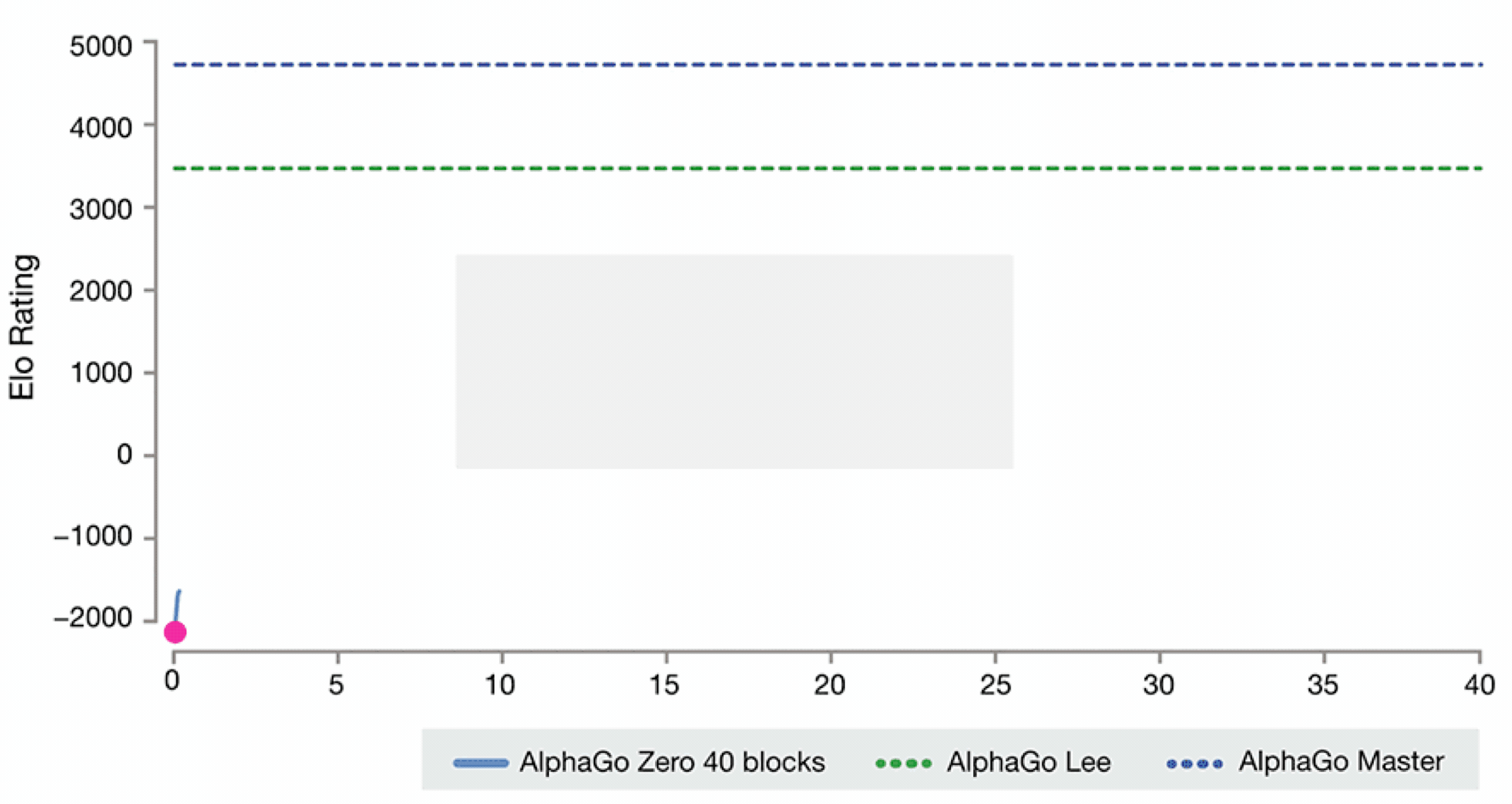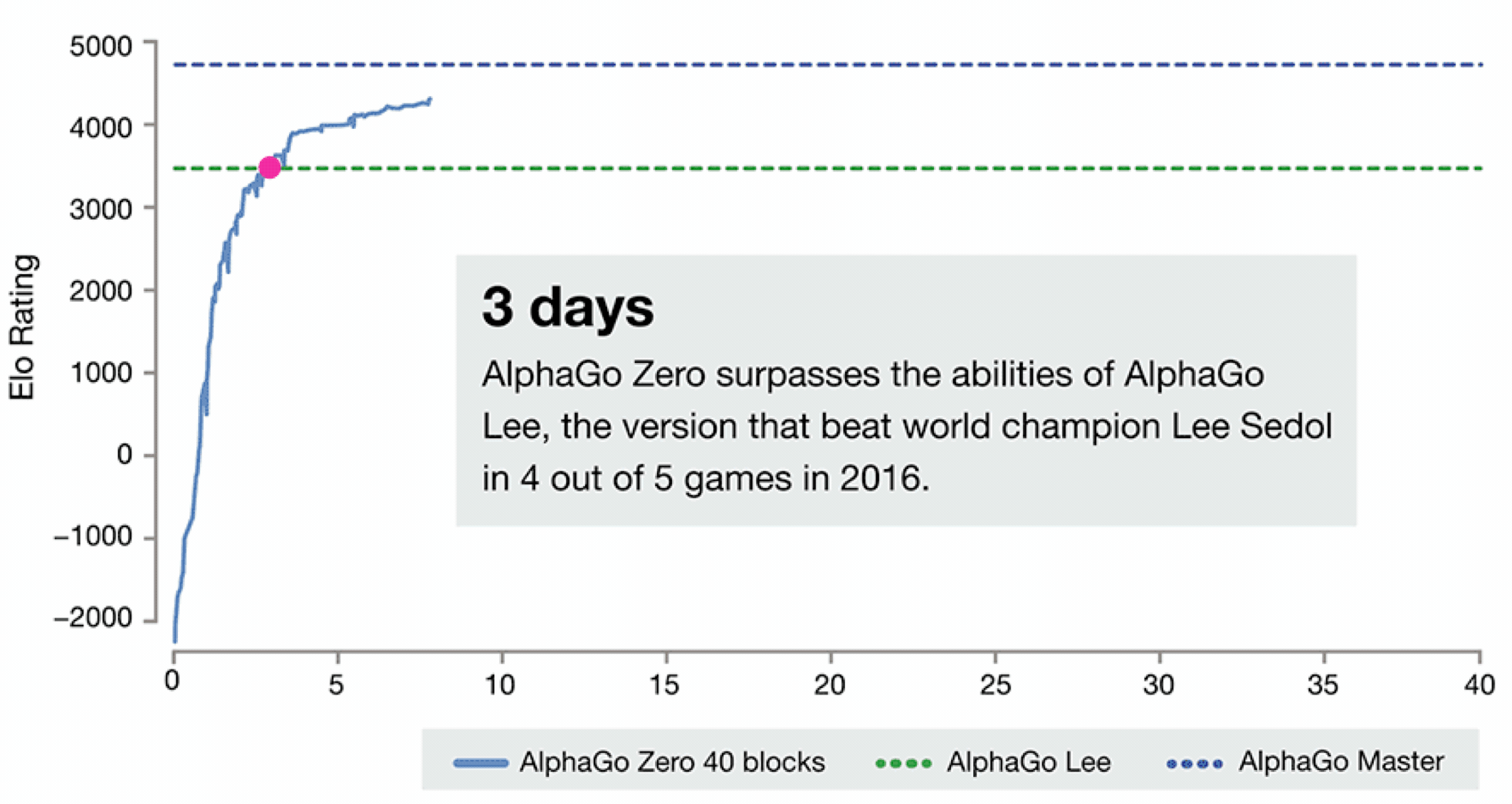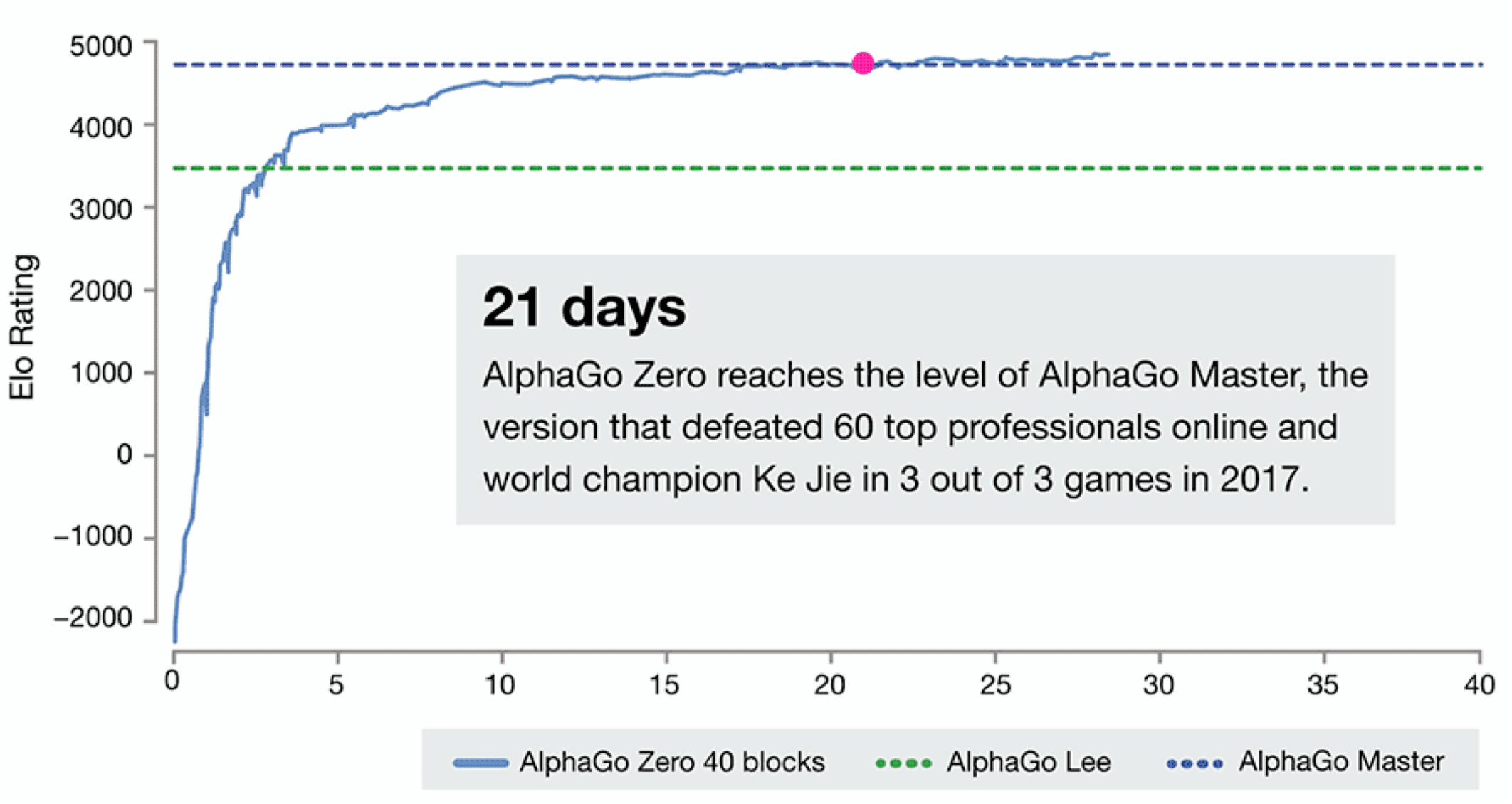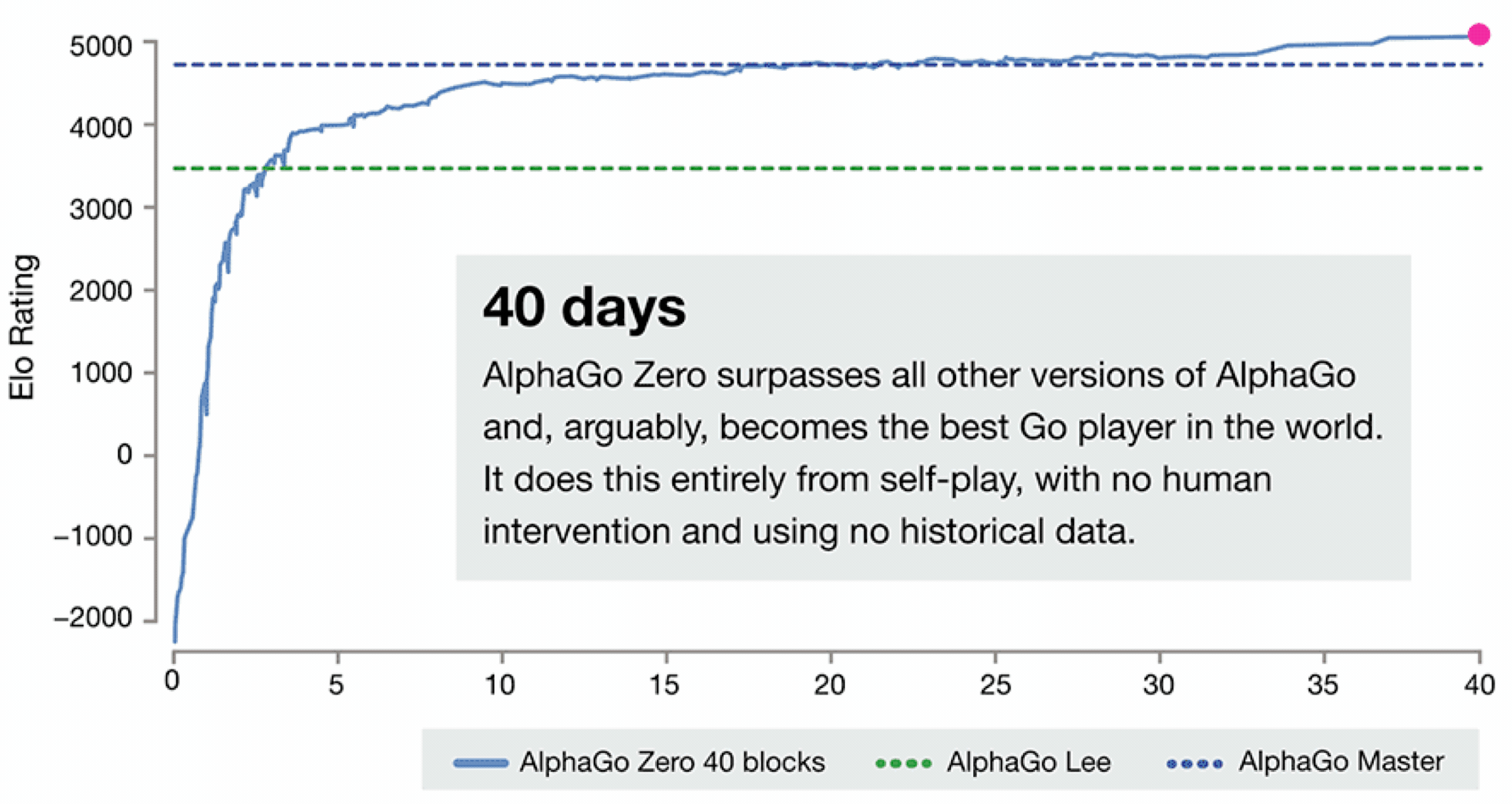
如下图, 大家可以看下AlphaGo的进化史, 想要详细了解的话可以查看 Alphago进化史 漫画告诉你Zero为什么这么牛
模型评估
利用测试集机型评估
- 验证模型是否正确
- 使用测试数据预测结果和正式结果进行比较
分类模型评估
- 准确率
- 预测正确的数占样本总数的比例。
- 精确率
- 正确预测为正占全部预测为正的比例
- 召回率
- 正确预测为正占全部正样本的比例
- F1-score
- 主要用于评估模型的稳健性
- AUC指标
- 主要用于评估样本不均衡的情况
回归模型评估
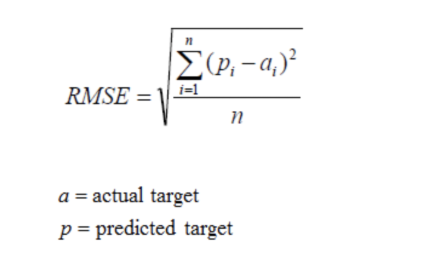
- 均方根误差(Root Mean Squared Error,RMSE)
RMSE是一个衡量回归模型误差率的常用公式。 然而,它仅能比较误差是相同单位的模型。
- 相对平方误差(Relative Squared Error,RSE)
与RMSE不同,RSE可以比较误差是不同单位的模型。
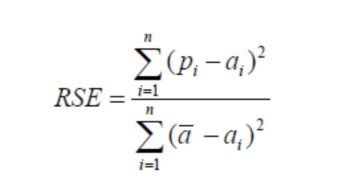
平均绝对误差(Mean Absolute Error,MAE)
MAE与原始数据单位相同, 它仅能比较误差是相同单位的模型。量级近似与RMSE,但是误差值相对小一些。
相对绝对误差(Relative Absolute Error,RAE)
与RSE不同,RAE可以比较误差是不同单位的模型。
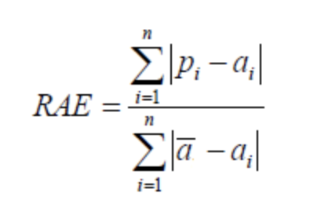
- 决定系数 (Coefficient of Determination)
决定系数 (R2)回归模型汇总了回归模型的解释度,由平方和术语计算而得。

R2描述了回归模型所解释的因变量方差在总方差中的比例。R2很大,即自变量和因变量之间存在线性关系,如果回归模型是“完美的”,SSE为零,则R2为1。R2小,则自变量和因变量之间存在线性关系的证据不令人信服。如果回归模型完全失败,SSE等于SST,没有方差可被回归解释,则R2为零。
拟合
模型评估用于评价训练好的的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
在训练过程中,你可能会遇到如下问题:
训练数据训练的很好啊,误差也不大,为什么在测试集上面有问题呢?
当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。
欠拟合
因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。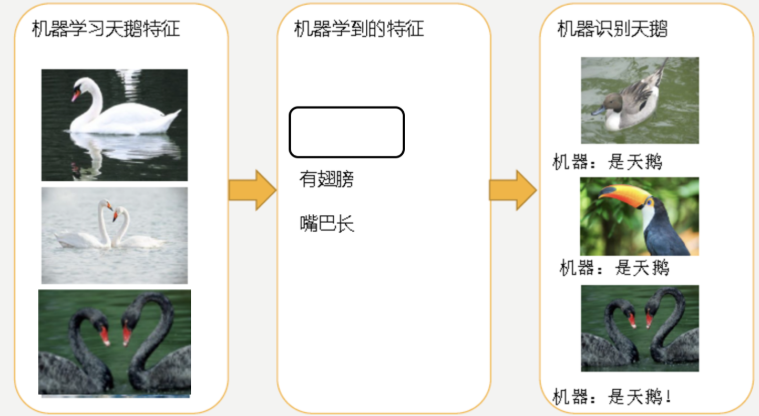
过拟合
机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
过拟合(over-fitting):所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。